고정 헤더 영역
상세 컨텐츠
본문
동시성 프로그래밍
현재의 프로그래밍은 순차적인 프로그램보다 다양한 기능이 한꺼번에 일어나는 다중 실행 환경에 있는 경우가 많아졌다.
여러 개의 루틴이 선행 작업의 순서나 완료 여부와 상관없이 실행되는 방식을 비동기적(asynchronous)이라고 한다.
이러한 비동기 프로그래밍은 RxJava, Reactive와 같은 서드파티(third-pary)라이브러리에서 제공하고 있다.
서드파티란?
보통 기본으로 제공되는 표준 라이브러리가 아닌 다른 개발자가 만든 라이브러리를 말한다.
개발을 편리하게 해주는 플러그인, 프레임워크, 유틸리티 API등을 제공하고 있다.
코틀린에서는 코루틴(Coroutine)을 서드파티가 아닌 기본으로 제공하고 있다.
코루틴이란?
하나의 개별적인 작업을 루틴(routine)이라고 부르는데 코루틴이란 여러 개의 루틴들이 협력(co)한다는 의미로 만들어진 합성어이다.
순차적으로 루틴을 실행하는 동기 코드는 코드의 복잡도가 낮지만, 코드의 여러 구간에서 요청된 작업이 마무리가 될 때까지 멈춰 있는 현상이 나타나게 된다. 이를 블로킹된 코드라고 부른다. 이것을 개선하기 위해서는 넌블로킹 기법을 사용해야한다. 다중 작업을 하려면 스레드와 같은 비동기 코드를 작성해야하는데 이때 코드가 복잡해진다. 블로킹과 넌블로킹을 또 알아보자.
아래 글을 최신버전으로 수행했는데, 아래 글을 통해 알아보자.
https://baseballgrammer.tistory.com/46
blocking 과 non-blocking assignment의 차이
베릴로그가 아닌 다이어그램을 통해 살펴보자. 위 다이어그램은 2개의 태스크가 있는 일반적인 형태의 프로그램 흐름이다. 먼저 태스크 A에서 블로킹 구간을 발견할 수 있다. 입출력 과정인 읽
baseballgrammer.tistory.com
프로세스와 스레드
태스크는 큰 실행 단위인 프로세스나 좀 더 작은 실행 단위인 스레드를 말한다.
하나의 프로그램이 실행되면 프로세스가 시작되는데 프로세스는 실행되는 메모리, 스택, 열린 파일 등을 모두 포함하기 때문에 프로세스 간 문맥교환(context-switching)을 할 때 많은 비용이 든다.
반면 스레드는 자신의 스택만 독립적으로 가지고 나머지는 대부분을 스레드끼리 공유하므로 문맥 교환 비용이 낮아 프로그래밍에서 많이 사용된다. 다만 여러 개의 스레드를 구성하면 코드가 복잡해진다. 이러한 멀티 스레드(multi-thread)를 구현하기 위해서는 저수준에서 운영체제의 개념과 스케줄링, 스레드와 프로세스에 대한 깊은 이해가 있어야한다.
코루틴을 통해 전동적인 스레드 개념보다 좀 더 쉽게 비동기 프로그래밍을 할 수 있다.
context-switching이 없고 최적화된 비동기 함수를 통해 비선점형으로 작동하는 특징이 있어 협력형 멀티태스킹을 구현할 수 있다.
협력형 멀티태스킹이란?
프로그램에서 태스크를 수행할 때 운영체제를 사용할 수 있게 하고 특정한 작업에 작업 시간을 할당하는 것을 '선점한다'라고 한다.
선점형 멀티태스킹은 운영체제가 강제로 태스크의 실행을 바꾸는 개념이고 협력형 멀티태스킹은 태스크들이 자발적으로 양보하며 실행을 바꿀 수 있는 개념이다.
스레드 생성하기
코틀린에서 스레드 루틴을 만들려면 Thread 클래스를 상속받거나 Runnable 인터페이스를 구현한다.
package chap11.section1
// Thread 클래스를 상속받아 구현하기
class SimpleThread: Thread(){
override fun run() {
println("Current Thread: ${Thread.currentThread()}")
}
}
// Runnable 인터페이스로부터 run() 메서드 구현하기
class SimpleRunnalbe: Runnable{
override fun run(){
println("Current Threads: ${Thread.currentThread()}")
}
}
fun main(){
val thread = SimpleThread()
thread.start()
val runnable = SimpleRunnalbe()
val thread1 = Thread(runnable)
thread1.start()
}
사용자 함수를 통한 스레드 생성하기
package chap11.section1
// 람다식을 추가로 만들어 실행
public fun thread(start: Boolean = true, isDaemon: Boolean = false, contextClassLoader: ClassLoader? = null,
name: String? = null, priority: Int = -1, block: () -> Unit) : Thread{
val thread = object : Thread(){
public override fun run(){
block()
}
}
if(isDaemon) // 백그라운드 실행여부
thread.isDaemon = true
if(priority > 0) // 우선순위 (1: 낮음 ~ 5: 보통 ~ 10: 높음)
thread.priority = priority
if (name != null) // 이름
thread.name = name
if (contextClassLoader != null)
thread.contextClassLoader = contextClassLoader
if (start)
thread.start()
return thread
}
fun main() {
// 스레드의 옵션 변수를 손쉽게 설정할 수 있음
thread(start = true){
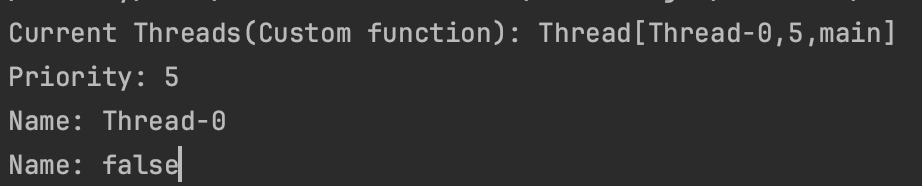
println("Current Threads(Custom function): ${Thread.currentThread()}")
println("Priority: ${Thread.currentThread().priority}") // 기본값은 5
println("Name: ${Thread.currentThread().name}")
println("Name: ${Thread.currentThread().isDaemon}")
}
}
스레드의 우선순위, 백그라운드 여부, 이름 등 스레드가 가져야 할 각종 옵션 변수를 손쉽게 설정할 수 있다.
옵션을 비워도 기본값이 적영되서 문제가 없다.
코루틴의 개념과 사용 방법
코루틴의 기본 개념
프로세스나 스레드는 해당 작업을 중단하고 다른 루틴을 실행하기 위한 문맥교환을 시도할 때 많이 비용이든다.
코루틴은 비용이 많이 드는 문맥 교환 없이 해당 루틴을 일시 중단해서 이러한 비용을 줄일 수 있다.
이 말은 운영체제가 스케줄링에 개입하는 과정이 필요하지 않다는 것이다.(일시 중단은 사용자가 제어할 수 있다.)
실습하기에 앞서 설치해야한다.
IntelliJ에서 coroutine을 설치하는 방법이다.
1. File -> Project Structure에 들어간다.
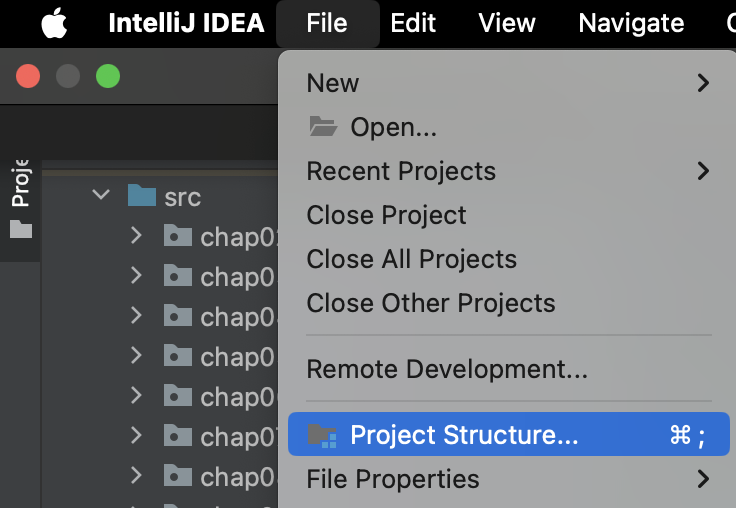
2. Libraries -> + 버튼 -> From Maven
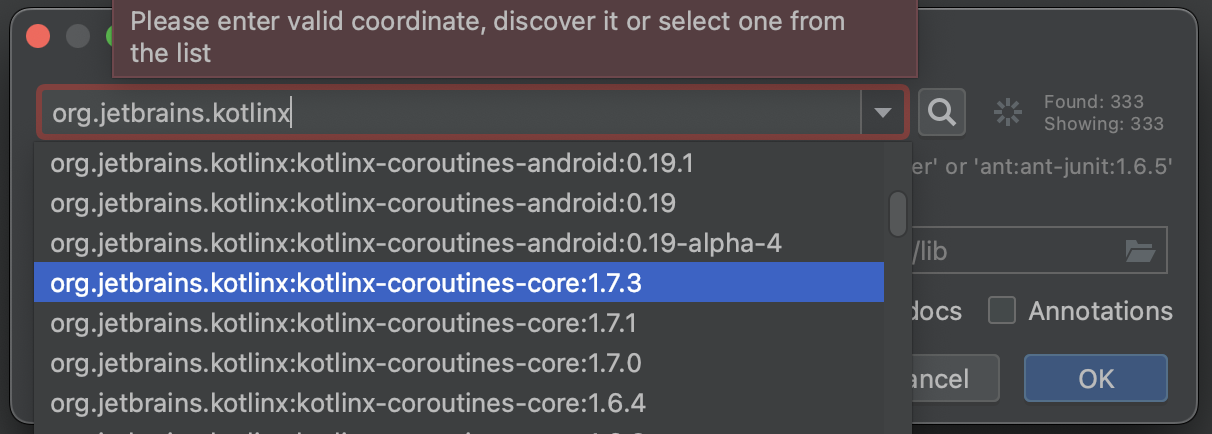
3. org.jetbrains.kotlinx를 검색한 후, kotlinx-coroutines-core:맞는버전 을 찾아서 OK -> Apply
코투린의 기본패키지는 다음과 같다.
| 기능 | 설명 |
| launch / async | 코루틴 빌더 |
| Job / Deferred | cancellation 지원 |
| Dispatchers | Default는 백그라운드 코루틴을 위한 것이고 Main은 Android나 Swing, JavaFx를 위해 사용 |
| delay / yield | 상위 레벨 지연(suspending) 함수 |
| Channel / Mutex | 통신과 동기화를 위한 기능 |
| coroutineScope / supervisorScope | 범위 빌더 |
| select | 표현식 지원 |
바로 예제를 보자.
package chap11.section2
import kotlinx.coroutines.*
fun main() { // 메인 스레드의 문맥
GlobalScope.launch{ // 새로운 코루틴을 백그라운드에 실행
delay(1000L) // 1초의 넌블로킹 지연(시간의 기본단위는 ms)
println("World!") // 지연 후 출력
}
println("Hello, ") // 메인 스레드의 코루틴이 지연되는 동안 계속 실행
Thread.sleep(2000L) // 메인 스레드가 JVM에서 바로 종료되지 않게 2초 기다림
}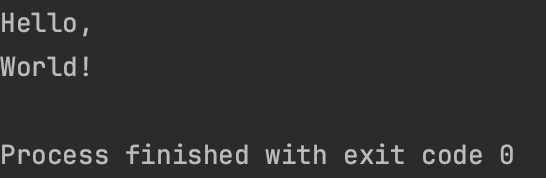
1초 후에 World!가 출력이 되고, 2초 후에 프로세스가 종료되었다고 출력이 되었다.
launch 코루틴 빌더 생성하기
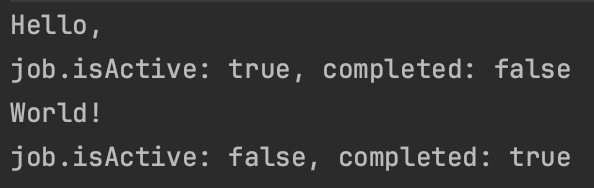
Job 객체를 받아 코루틴의 상태를 출력해 보는 예제이다.
package chap11.section2
import kotlinx.coroutines.*
fun main() { // 메인 스레드의 문맥
val job = GlobalScope.launch{ // 새로운 코루틴을 백그라운드에 실행
delay(1000L) // 1초의 넌블로킹 지연(시간의 기본단위는 ms)
println("World!") // 지연 후 출력
}
println("Hello, ") // 메인 스레드의 코루틴이 지연되는 동안 계속 실행
println("job.isActive: ${job.isActive}, completed: ${job.isCompleted}")
Thread.sleep(2000L) // 메인 스레드가 JVM에서 바로 종료되지 않게 2초 기다림
println("job.isActive: ${job.isActive}, completed: ${job.isCompleted}")
}
코루틴의 순차적 실행
package chap11.section2
import kotlinx.coroutines.*
suspend fun doWork1(): String{
delay(1000)
return "Work1"
}
suspend fun doWork2(): String{
delay(3000)
return "Work2"
}
private fun worksInSerial(){
// 순차적 실행
GlobalScope.launch {
val one = doWork1()
val two = doWork2()
println("Kotlin One : $one")
println("Kotlin Two : $two")
}
}
fun main(){
worksInSerial()
readLine() // main이 먼저 정료되는 것을 방지하기 위해 콘솔에서 [Enter] 입력 대기
}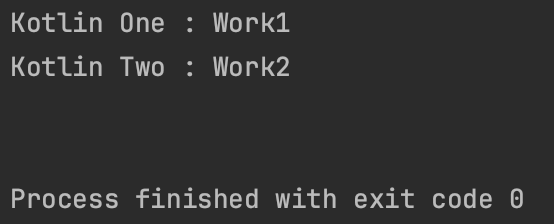
suspend 키워드를 사용한 2개으 함수를 정의하고 그 안에 시간이 다른 delay함수를 사용했다.
async 코루틴 빌더 생성하기
package chap11.section2
import kotlinx.coroutines.*
suspend fun doWork1(): String{
delay(1000)
return "Work1"
}
suspend fun doWork2(): String{
delay(3000)
return "Work2"
}
private fun worksInParallel(){
// Deferred<T>를 통해 결괏값을 반환
val one = GlobalScope.async{
doWork1()
}
val two = GlobalScope.async{
doWork2()
}
GlobalScope.launch{
val combined = one.await() + "_" + two.await()
println("kotlin Combined : $combined")
}
}
fun main(){
worksInParallel()
readLine() // main이 먼저 정료되는 것을 방지하기 위해 콘솔에서 [Enter] 입력 대기
}
블로킹 모드로 동작시키기
package chap11.section2
import kotlinx.coroutines.*
fun main() = runBlocking<Unit> { // main() 함수가 코루틴 환경에서 실행
launch{ // 백그라운드로 코루틴 실행
delay(1000L)
println("World!")
}
println("Hello") // 즉시 이어서 실행됨
// delay(2000L> // delay 함수를 사용하지 않아도 코루틴을 기다림
}
join함수의 결과 기다리기
package chap11.section2
import kotlinx.coroutines.*
fun main() = runBlocking<Unit> { // main() 함수가 코루틴 환경에서 실행
val job = launch{ // Job의 객체를 반환
delay(1000L)
println("World!")
}
println("Hello") // 즉시 이어서 실행됨
job.join() // 명시적으로 코루틴이 완료되길 기다림. 취소할 경우 job.cancel() 함수를 사용
// delay(2000L> // delay 함수를 사용하지 않아도 코루틴을 기다림
}
Job이란?
Job은 백그라운드에서 실행하는 작업을 가리킨다. 개념적으로 간단한 생명주기를 가지고 있고 부모-자식 관계가 형성되면 부모가 작업이 취소될 때 하위 자식의 작업이 모두 최소된다. 보통 Job() 팩토리 함수나 launch에 의해 job객체가 생성된다. job 객체는 다음의 상태를 가진다.
| 상태 | isActive | isCompleted | isCancelled |
| New | false | false | false |
| Active(기본값 상태) | true | false | false |
| Completing | true | false | false |
| Cancelling | false | false | true |
| Cancelled(최종 상태) | false | true | true |
| Completed(최종 상태) | false | true | false |
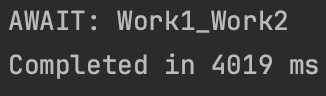
async함수를 통해 시작 시점을 조절할 수 있는데, 아래 예시는 시작시점을 늦춘 예시이다.
package chap11.section2.starttest
import kotlinx.coroutines.CoroutineStart
import kotlinx.coroutines.async
import kotlinx.coroutines.delay
import kotlinx.coroutines.runBlocking
import kotlin.system.measureTimeMillis
suspend fun doWork1(): String{
delay(1000)
return "Work1"
}
suspend fun doWork2(): String{
delay(3000)
return "Work2"
}
fun main() = runBlocking{
val time = measureTimeMillis {
val one = async(start = CoroutineStart.LAZY) {doWork1()}
val two = async(start = CoroutineStart.LAZY) {doWork2()}
println("AWAIT: ${one.await() + "_" + two.await()}")
}
println("Completed in $time ms")
}
많은 양의 작업을 생성해보자! 대략 10만개쯤?
package chap11.section2
import kotlinx.coroutines.delay
import kotlinx.coroutines.launch
import kotlinx.coroutines.runBlocking
fun main() = runBlocking {
val jobs = List(100_000) { // 많은 양의 코루틴을 위한 List
launch{
delay(1000L)
print(".")
}
}
jobs.forEach{it.join()} // 모든 jobs가 완료될 때까지 기다림
}
10만개의 점이 찍힌다.
코루틴과 시퀀스
코틀린의 표준 라이브러리 중에서 sequence()를 사용하면 아주 많은 값을 만들어 내는 코드로부터 특정 값의 범위를 가져올 수 있다.
sequence함수는 sequence<T>를 반환하는데 Sequence() 함수 내부에서 지연함수를 사용할 수 있고, 코루틴과 함께 최종 형태를 나중에 결정할 수 있는 늦은(lazy) 시퀀스를 만들 수 있다.
예시를 보자.
package chap11.section2
val fibonacciSeq = sequence{
var a = 0
var b = 1
yield(1) // 지연 함수가 사용됨
while(true){
yield(a+b)
val tmp = a+b
a = b
b = tmp
}
}
fun main() {
println(fibonacciSeq.take(8).toList()) // 8개의 값을 획득
}
sequence 블록에서 지연 함수인 yield() 함수를 호출하면서 코루틴을 생성한다.
코루틴 동작 제어하기
코루틴의 문맥
코루틴은 항상 특정 문맥에서 실행된다.
이때 어떤 문맥에서 코루틴을 실행할지는 디스패치가 결정한다.
package chap11.section3
import kotlinx.coroutines.*
fun main() = runBlocking<Unit> {
val jobs = arrayListOf<Job>()
jobs += launch(Dispatchers.Unconfined) { // 메인 스레드에서 작업
println("Unconfined: \t\t ${Thread.currentThread().name}")
}
jobs += launch(coroutineContext) { // 부모의 문맥, 여기서는 runBlokcing의 문맥
println("coroutineContext: \t ${Thread.currentThread().name}")
}
jobs += launch(Dispatchers.Default) { // 디스패치의 기본값
println("Default: \t\t ${Thread.currentThread().name}")
}
jobs += launch(Dispatchers.IO) { // 입출력 중심의 문맥
println("IO: \t ${Thread.currentThread().name}")
}
jobs += launch { // 아무런 인자가 없을 때
println("main runBlocking: ${Thread.currentThread().name}")
}
jobs += launch(newSingleThreadContext("MyThread")) { // 새 스레드를 생성
println("MyThread: \t\t ${Thread.currentThread().name}")
}
jobs.forEach{it.join()}
}
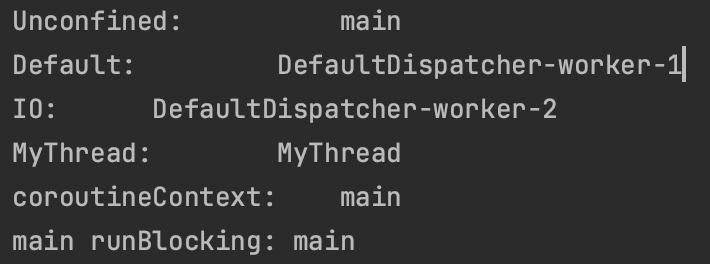
기본 동작 제어하기
repeat()를 통한 반복
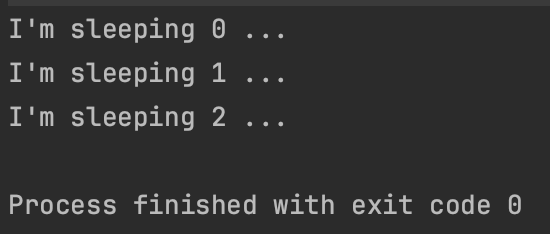
package chap11.section3
import kotlinx.coroutines.GlobalScope
import kotlinx.coroutines.delay
import kotlinx.coroutines.launch
import kotlinx.coroutines.runBlocking
fun main() = runBlocking <Unit>{
GlobalScope.launch{ // 만일 launch만 사용하면 종료되지 않음
repeat(1000){ i ->
println("I'm sleeping $i ...")
delay(500L)
}
}
delay(1300L)
}
cancel를 통한 작업 취소
package chap11.section3
import kotlinx.coroutines.delay
import kotlinx.coroutines.launch
import kotlinx.coroutines.runBlocking
fun main() = runBlocking <Unit>{
val job = launch{ // 만일 launch만 사용하면 종료되지 않음
repeat(1000){ i ->
println("I'm sleeping $i ...")
delay(500L)
}
}
delay(1300L)
job.cancel()
}
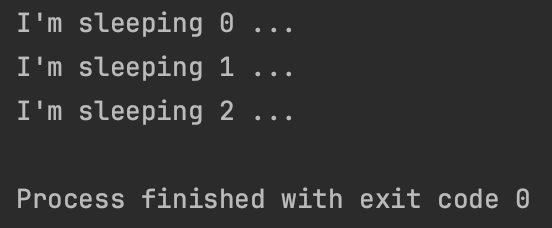
finally의 실행보장
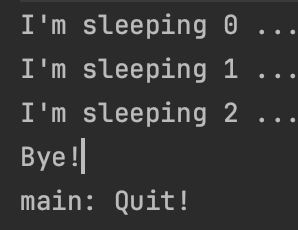
package chap11.section3
import kotlinx.coroutines.cancelAndJoin
import kotlinx.coroutines.delay
import kotlinx.coroutines.launch
import kotlinx.coroutines.runBlocking
fun main() = runBlocking <Unit>{
val job = launch { // 만일 launch만 사용하면 종료되지 않음
try {
repeat(1000) { i ->
println("I'm sleeping $i ...")
delay(500L)
}
} finally{
println("Bye!")
}
}
delay(1300L)
job.cancelAndJoin() // 작업을 취소하고 완료될 떄까지 기다림
println("main: Quit!")
}
상태 판단
package chap11.section3
import kotlinx.coroutines.*
fun main() = runBlocking <Unit>{
val startTime = System.currentTimeMillis()
val job = GlobalScope.launch {
var nextPrintTime = startTime
var i = 0
while(i<5){ // 조건을 계산에 의해 반복
if(System.currentTimeMillis() >= nextPrintTime){
println("I'm sleeping ${i++} ...")
nextPrintTime += 500L
}
}
}
delay(1300L)
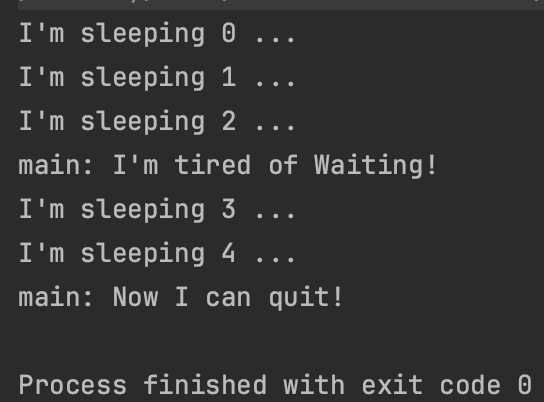
println("main: I'm tired of Waiting!")
job.cancelAndJoin() // 작업을 취소하고 완료될 떄까지 기다림
println("main: Now I can quit!")
}
시간만료
package chap11.section3
import kotlinx.coroutines.TimeoutCancellationException
import kotlinx.coroutines.delay
import kotlinx.coroutines.runBlocking
import kotlinx.coroutines.withTimeout
fun main() = runBlocking<Unit> {
try{
withTimeout(1300L){ // timeout 예외 발생, Null로 처리하는 걍우 withTimeoutOrNull()을 사용
repeat(1000){i ->
println("I'm sleeping $i ...")
delay(500L)
}
}
}catch (e: TimeoutCancellationException){
println("timed put with $e")
}
}

채널의 동작
채널은 자료를 주고받기 위한 일종의 통로이다.
넌블로킹 전송 개념으로 사용되고 있다.
SendChannel과 ReceiveChannel 인터페이스를 이용해 값들의 스트림을 전송하는 방법을 제공한다.
바로 예시로 알아보자.
package chap11.section3
import kotlinx.coroutines.channels.Channel
import kotlinx.coroutines.launch
import kotlinx.coroutines.runBlocking
fun main() = runBlocking<Unit> {
val channel = Channel<Int>()
launch {
// 여기에 다량의 CPU연산 작업이나 비동기 로직을 둘 수 있음
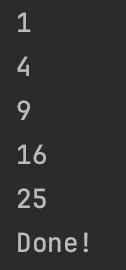
for(x in 1..5) channel.send(x * x)
}
repeat(5){println(channel.receive())} // 5개의 값을 채널로부터 받음
println("Done!")
}
produce 생산자 소비자 패턴
produce는 채널이 붙어 있는 코루틴으로 생산자 측면의 코드를 쉽게 구성할 수 있다.
채널에 값을 보내면 생산자로 볼 수 있고 소비자는 consumeEach 함수를 확장해 for문을 대신 해서 저장된 요소를 소비한다.
package chap11.section3
import kotlinx.coroutines.CoroutineScope
import kotlinx.coroutines.channels.ReceiveChannel
import kotlinx.coroutines.channels.consumeEach
import kotlinx.coroutines.channels.produce
import kotlinx.coroutines.runBlocking
// 생산자를 위한 함수 생성
fun CoroutineScope.producer(): ReceiveChannel<Int> = produce {
var total: Int = 0
for (x in 1..5){
total += x
send(total)
}
}
fun main() = runBlocking {
val result = producer() // 값의 생산
result.consumeEach { print("$it ") } // 소비자 루틴 구성
}

버퍼를 가진 채널
채널에는 기본 버퍼가 없으므로 send() 함수가 먼저 호출되면 receive() 함수가 호출되기 전까지 send() 함수는 일시 지연된다.
반대의 경우도 receive() 함수가 호출되면 send()함수가 호출되기 전까지 receive()함수는 지연된다.
하지만 채널에 버퍼 크기를 주면 지연없이 여러 개의 요소를 보낼 수 있게 된다.
Channel() 생성자에는 capacity 매개변수가 있으며 이것이 버퍼 크기를 정한다.
package chap11.section3
import kotlinx.coroutines.channels.Channel
import kotlinx.coroutines.delay
import kotlinx.coroutines.launch
import kotlinx.coroutines.runBlocking
fun main() = runBlocking<Unit>{
val channel = Channel<Int>(3) // 버퍼 capacity 값을 줌
val sender = launch(coroutineContext){ // 송신자 측
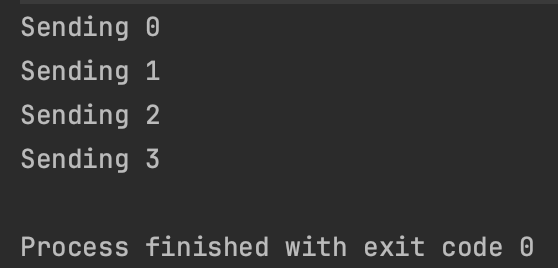
repeat(10){
println("Sending $it")
channel.send(it) // 지속적으로 보내다가 꽉 차면 일시 지연
}
}
delay(1000) // 아무것도 받지 않고 1초 기다린 후
sender.cancel() // 송신자의 작업을 취소
}
select 표현식
다양한 채널에서 무언가 응답해야 한다면 각 채널의 실행시간에 따라 결과가 달라질 수 있는데 이때 select를 사용하면 표현식을 통해 결과를 받을 수 있다.
package chap11.section3
import kotlinx.coroutines.GlobalScope
import kotlinx.coroutines.channels.produce
import kotlinx.coroutines.delay
import kotlinx.coroutines.runBlocking
import kotlinx.coroutines.selects.select
import java.util.*
fun main() = runBlocking {
val routine1 = GlobalScope.produce{
delay(Random().nextInt(1000).toLong())
send("A")
}
val routine2 = GlobalScope.produce{
delay(Random().nextInt(1000).toLong())
send("B")
}
val result = select<String> { // 먼저 수행된 것을 받게 된다.
routine1.onReceive { result -> result}
routine2.onReceive{result -> result}
}
println("Result was $result")
}먼저 수행된 것을 받은 결과이다.

공유 데이터 문제 알아보기
병행 프로그래밍에서는 전역 변수 같은 변경 가능한 공유 자원에 접근할 때 값의 무결성을 보장할 수 있는 방법이 있다.
코틀린에서는 공유 자원의 보호와 스레드 안전을 구현하기 위해 원자 변수, 스레드 가두기, 상호 배제등을 사용할 수 있다.
기존 자바의 기법과 코틀린에서 추가된 기법들을 알아보자.
동기화 기법
synchronized 메서드와 블록
스레드 간 서로 공유하는 데이터가 있을 때 동기화해서 데이터의 안정성을 보장한다.
특정 스레드가 이미 자원을 사용하는 중이면 나머지 스레드의 접근을 먹는것이다.
코틀린에서는 @Synchronized 애노테이션 표기법을 사용해야한다.
자바의 volatile도 같은 방법으로 사용할 수 있다.
보통 변수는 성능 때문에 데이터를 캐시에 넣어 두고 작업하는데 이때 여러 스레드로부터 값을 읽거나 쓰면 데이터가 일치하지 않고 깨진다.
이것을 방지하기 위해 데이터를 캐시에 넣지 않도록 volatile 키워드와 함께 변수를 선언할 수 있다.
또 volatile 키워드를 사용하면 코드가 최적화되면서 순서가 바뀌는 경우도 방지할 수 있다.
정리하자면 volatile은 의도한 순서대로 읽기 및 쓰기를 할 수 있다
하지만 두 스레드에서 공유 변수에 대한 읽기 쓰기는 volatile키워드로 부족해서 synchronized를 통해 연산의 원자성을 보장해줘야한다.
아래 예시로 보자.
package chap11.section4
import kotlin.concurrent.thread
@Volatile private var running = false
private var count = 0
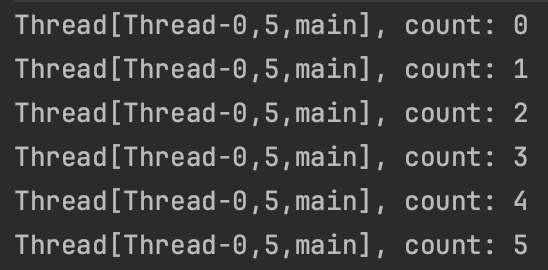
fun start() {
running = true
thread(start = true){
while(running)
println("${Thread.currentThread()}, count: ${count++}")
}
}
fun stop(){ running = false }
fun main(){
start()
start()
Thread.sleep(10)
stop() // 여기서 상태를 바꿈
}
일정 시간이 지난 후 stop() 함수에 의해 running의 상태를 변경하고 start() 함수의 while 조건이 false가 되면서 프로그램이 중단된다.
@volatile은 값 쓰기에 대해서는 보장하지 않아 여전히 원자성 보장이 필요하다.
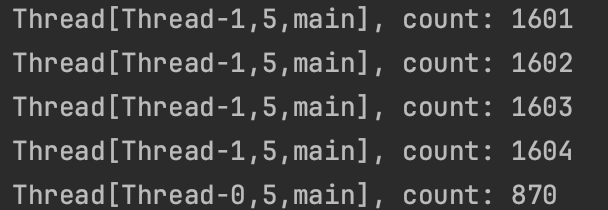
원자 변수
특정 변수의 증가나 감소, 더하기나 빼기가 단일 기계어 명령으로 수행되는 것을 말하며 해당 연산이 수행되는 도중에는 누구도 방해하지 못하기 때문에 값의 무결성을 보장할 수 있다.
package chap11.section4
import kotlinx.coroutines.GlobalScope
import kotlinx.coroutines.launch
import kotlinx.coroutines.runBlocking
import kotlin.system.measureTimeMillis
var counter = 0 // 병행 처리 중 문제가 발생할 수 있는 변수
suspend fun massiveRun(action: suspend() -> Unit){
val n = 1000 // 실행할 코루틴의 수
val k = 1000 // 각 코루틴을 반복할 수
val time = measureTimeMillis {
val jobs = List(n){
GlobalScope.launch{
repeat(k) {action()}
}
}
jobs.forEach {it.join()}
}
println("Completed ${n * k} actions in $time ms")
}
fun main() = runBlocking<Unit> {
massiveRun {
counter++ // 증가 연산에서 값에서 무결성에 문제가 발생할 수 있음
}
println("Counter = $counter")
}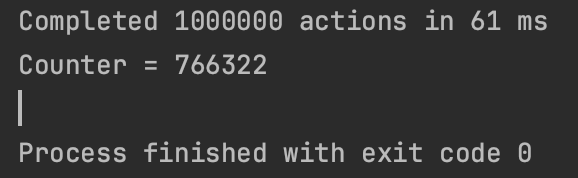
위 코드에서 counter 변수의 값을 증가시키는 연산을 하고 있다.
순차적 프로그램에서는 문제가 없으나 많은 수의 독립적인 루틴이 이 코드에 접근해 counter를 공유하면 언제는 코드가 중단될 수 있음을 생각해야한다. 중단 시점은 CPU의 최소 단위인 명령어가 실행될때 결정된다. 코드상에서는 counter++이라는 한 줄의 코드이지만 이것이 컴파일되서 CPU가 실행할 명령어로 변환되면 여러 개의 명령어로 분할되므로 프로그래머가 예상하지 못한 결과를 초래할 수도 있습니다. 즉, counter의 증가를 시작했지만 CPU의 최소 명령어가 마무리되지 않은 시점에 루틴이 중단되어서 다른 루틴이 counter를 건드릴 수 있다.(내부적으로 값이 증가되지 못하고 다른 루틴이 실행됨) 이때 다른 루틴이 해당 변수를 조작할 수 있기때문에 값의 무결성을 보장할 수 없다. 실행 결과가 매번 달라질 수 있다.
아래코드는 위의 문제점을 해결할 수 있다.
package chap11.section4
import kotlinx.coroutines.GlobalScope
import kotlinx.coroutines.launch
import kotlinx.coroutines.runBlocking
import java.util.concurrent.atomic.AtomicInteger
import kotlin.system.measureTimeMillis
// var counter = 0 // 병행 처리 중 문제가 발생할 수 있는 변수
var counter = AtomicInteger(0) // 원자 변수로 초기화
suspend fun massiveRun(action: suspend() -> Unit){
val n = 1000 // 실행할 코루틴의 수
val k = 1000 // 각 코루틴을 반복할 수
val time = measureTimeMillis {
val jobs = List(n){
GlobalScope.launch{
repeat(k) {action()}
}
}
jobs.forEach {it.join()}
}
println("Completed ${n * k} actions in $time ms")
}
fun main() = runBlocking<Unit> {
massiveRun {
// counter++ // 증가 연산에서 값에서 무결성에 문제가 발생할 수 있음
counter.incrementAndGet() // 원자 변수의 멤버 메서드를 사용해 증가
}
// println("Counter = $counter")
println("Counter = ${counter.get()}") // 값 읽기
}

스레드 가두기
스레드 가두기는 위 문제를 해결 할 또 다른 방법이다.
package chap11.section4.confinement
import kotlinx.coroutines.*
import kotlin.coroutines.CoroutineContext
import kotlin.system.measureTimeMillis
val counterContext = newSingleThreadContext("CounterContext")
var counter = 0
suspend fun massiveRun(context: CoroutineContext, action: suspend() -> Unit){
val n = 1000
val k = 1000
val time = measureTimeMillis {
val jobs = List(n){
GlobalScope.launch(context){
repeat(k) {action () }
}
}
jobs.forEach {it.join()}
}
println("Completed ${n * k} actions in $time ms")
}
fun main() = runBlocking<Unit>{
massiveRun(counterContext){
counter++
}
println("Counter = $counter")
}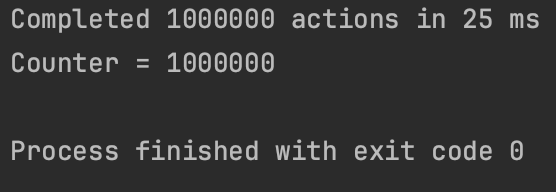
원자변수를 사용하는것보다 빠른것을 알 수 있다.
상호 배제
OS 과목에서 mutual exclusion으로 많이 봤을 것이다.
임계 구역(critical section)에 있는 경우 절대로 동시성이 일어나지 않게 하고 하나의 루틴만 접근하는 것을 보장한다.
임계 구역 또는 공유 변수 영역은 병렬 컴퓨팅에서 둘 이상의 스레드가 동시에 접근해서는 안 되는 베타적 공유 자원의 영역으로 정의할 수 있다.
임계 구역은 잘못된 변경이 일어나지 않도록 보호해야 하는 코드가 있는 구역이므로 임계 영역의 처리가 필요한 경우 임계구역에 들어간 루틴은 다른 루틴이 못 들어오도록 lock을 걸어야한다.
큰 특징은 소유자 개념이 있는데 일단 lock 루틴만이 lock을 해제할 수 있다.
다른 루틴은 lock을 할 수 없다.
package chap11.section4.mutex
import kotlinx.coroutines.sync.Mutex
import kotlinx.coroutines.*
import kotlinx.coroutines.sync.withLock
import kotlin.coroutines.CoroutineContext
import kotlin.system.measureTimeMillis
val counterContext = newSingleThreadContext("CounterContext")
var counter = 0
val mutex = Mutex()
suspend fun massiveRun(context: CoroutineContext, action: suspend() -> Unit){
val n = 1000
val k = 1000
val time = measureTimeMillis {
val jobs = List(n){
GlobalScope.launch(context){
repeat(k) {action () }
}
}
jobs.forEach {it.join()}
}
println("Completed ${n * k} actions in $time ms")
}
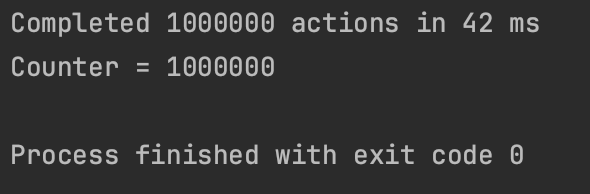
fun main() = runBlocking<Unit>{
massiveRun(counterContext){
mutex.withLock { // lock
counter++ // 임계 구역 코드
}
}
println("Counter = $counter")
}
이 밖에도 Mutex에는 검사를 위한 프로퍼티 isLocked가 있다. isLocked는 mutex가 잠금 상태일 때 true를 반환한다. onLock은 잠금 상태로 들어갈 때 select 표현식을 사용해 특정지연 함수를 선택할 수 있다.
actor 코루틴 빌더
코루틴의 결합으로 만든 actor는 코루틴과 채널에서 통신하거나 상태를 관리한다.
다른 언어의 actor 개념은 들어오고 나가는 메일 박스 기능과 비슷하지만 코틀린에서는 들어오는 메일 박스 기능만 한다고 볼 수 있다.
이벤트 루프
앞에서 배운 바와 같이 넌블로킹과 비동기 프로그래밍을 구현하다 보면 관련 라이브러리를 많이 접할 수 있게 된다.
보통 이러한 라이브러리를 통해 이벤트 처리를 위한 프로그래밍 모델을 만들기 위해 이벤트 루프를 사용하곤 한다.
이벤트 루프란 사용자와 상호작용하기 위해서는 항상 이벤트를 기다리며 감시하는 주체가 필요하며(wait for event), 이벤트가 발생하면 이것을 처리(dispatch)하기 위해 특정 루틴을 동작시켜야 한다. 바로 이러한 것들이 이벤트 루프가 할 일이다.
이벤트 루프는 각 이벤트 요청에 대한 이벤트 큐를 가지며 이벤트 큐는 이벤트 루프에 의해 처리할 핸들러인 작업자 스레드가 결정되어 실행된다.
이벤트 큐의 실행이 끝나면 이벤트 루프에 의해 다시 이벤트 큐의 위치로 돌아간다.
'책 리뷰 > Do it! 코틀린 프로그래밍' 카테고리의 다른 글
| 12주차 - 안드로이드 앱 개발과 코틀린 (0) | 2024.01.16 |
|---|---|
| 10주차 - 표준 함수와 파일 입출력 (0) | 2024.01.12 |
| 9주차 - 컬렉션 (1) | 2024.01.11 |
| 8주차 - 제네릭과 배열 (1) | 2024.01.11 |
| 7주차 - 다양한 클래스와 인터페이스 (0) | 2024.01.09 |





댓글 영역