고정 헤더 영역
상세 컨텐츠
본문

컬렉션이란 관련 있는 데이터를 모아 저장할 수 있는 자료구조이다.
컬렉션의 구조와 기본
컬렉션의 종류
List, Set, Map 등이 있으며 자바와는 다르게 불변형(immutable)과 가변형(mutable)로 나뉜다.
컬렉션의 자료형 및 생성 헬퍼 함수
| 컬렉션 | 불변형(읽기 전용) | 가변형 |
| List | listOf | mutableListOf, arrayListOf |
| Set | setOf | mutableSetOf, hashSetOf, linkedSetOf, sortedSetOf |
| Map | mapOf | mutableMapOf, hashMapOf, linkedMapOf, sortedMapOf |
변수를 선언할 때 불변형 val의 사용을 권장하듯이, 컬렉션도 읽기 전용인 불변형 선언을 권장한다.
collection 인터페이스의 멤버이다.
| 멤버 | 설명 |
| size | 컬렉션의 크기를 나타낸다. |
| isEmpty() | 컬렉션이 비어 있으면 true를 반환한다. |
| contains(element: E) | 특정 요소가 있다면 true를 반환한다. |
| containsAll(elements: Collection<E>) | 인자로 받아들인 컬렉션이 있다면 true를 반환한다. |
MutableCollection 인터페이스의 멤버 메서드이다.
| 멤버 메서드 | 설명 |
| add(element: E) | 인자로 전달 받은 요소를 추가하고 true를 반환하며, 이미 요소가 있거나 중복이 허용되지 않으면 false를 반환한다. |
| remove(element: E) | 인자로 전달 받은 요소를 삭제하고 true를 반환하며, 삭제하려는 요소가 없다면 false를 반환한다. |
| addAll(elements: Collection<E>) | 컬렉션을 인자로 전달 받아 모든 요소를 추가하고 true를 반환하며, 실패하면 false를 반환한다. |
| removeAll(elements: Collection<E>) | 컬렉션을 인자로 전달 받아 모든 요소를 삭제하고 true를 반환하며, 실패하면 false를 반환한다. |
| retainAll(elements: Collection<E>) | 인자로 전달받은 컬렉션의 요소만 보유한다. 성공하면 true를 반환하고, 실패하면 false를 반환한다. |
| clear() | 컬렉션의 모든 요소를 삭제한다. |
List 활용하기
앞에서 헬퍼 함수가 나왔는데, 헬퍼함수가 무엇일까?
보통 List와 같은 컬렉션은 직접 사용해 생성하지 않고 특정 함수의 도움을 통해 생성하는데 이때 사용자는 함수를 보통(Helper) 함수라고 한다.
불변형 List를 사용해보자.
package chap09.section2
fun main() {
// 불변형 List의 사용
var numbers: List<Int> = listOf(1,2,3,4,5)
var names: List<String> = listOf("one", "two", "three")
for (name in names){
println(name)
}
for (num in numbers) print(num) // 한 줄에서 처리하기
println() // 내용이 없을 때는 한 줄 내리는 개행
}
emptyList()함수
비어 있는 List를 생성하려면 emptyList<>()를 사용할 수 있다.
반드시 형식 매개변수를 지정해야한다.
val emptyList: List<String> = emptyList<String>()
listOfNotNull()함수
listOfNotNull()로 초기화하면 Null을 제외한 요소만 반환해 List를 구성할 수 있다.
val nonNullsList: List<Int> = listOfNotNull(2, 45, 2, null, 5, null)
println(nonNullsList)실행 결과 [2, 45, 2, 5]
List의 주요 멤버 메서드는 아래와 같다.
| 멤버 메서드 | 설명 |
| get(index:int) | 특정 인덱스를 인자로 받아 해당 요소를 반환한다. |
| indexOf(element: E) | 인자로 받은 요소가 첫 번째로 나타나는 인덱스를 반환하며, 없으면 -1을 반환한다. |
| lastIndexOf(element: E) | 인자로 받은 요소가 마지막으로 나타나는 인덱스를 반환하며, 없으면 -1을 반환한다. |
| listIterator() | 목록에 있는 iterator를 반환한다. |
| subList(fromIndex: Int, toIndex: Int) | 특정 인덱스의 from과 to 범위에 있는 요소 목록을 반환한다. |
멤버 메서드들을 사용해보자.
package chap09.section2
fun main() {
var names: List<String> = listOf("one", "two", "three")
println(names.size) // List 크기
println(names.get(0)) // 해당 인덱스의 요소 가져오기
println(names.indexOf("three")) // 해당 요소의 인덱스 가져오기
println(names.contains("two")) // 포함 여부 확인 후 포함되어 있으면 true 반환
}
가변형 List 생성하기
가변형 arrayListof() 함수
헬퍼 함수의 원형은 다음과 같다.
public fun <T> arrayListOf(vararg elements: T): ArrayList<T>
package chap09.section2
fun main() {
// 가변형 List를 생성하고 자바의 ArrayList로 반환
val stringList: ArrayList<String> = arrayListOf<String>("Hello", "Kotlin", "Wow")
stringList.add("Java") // 추기
stringList.remove("Hello") // 삭제
println(stringList)
}
가변형 mutableListOf() 함수
public fun <T> mutableListOf(vararg elements: T): MutableList<T>
package chap09.section2
fun main() {
// 가변형 List의 생성 및 추가, 삭제, 변경
val mutableList: MutableList<String> = mutableListOf<String>("Kildong", "Dooly", "Chelsu")
mutableList.add("Ben") // 추가
mutableList.removeAt(1) // 인덱스 1번 삭제
mutableList[0] = "Sean" // 인덱스 0번을 변경, set(index: Int, element: E)와 같은 역할
println(mutableList)
// 자료형의 혼합
val mutableListMixed = mutableListOf("Android", "Apple", 5, 6, 'X')
println(mutableListMixed)
}
List와 배열의 차이
C언어를 공부한사람이라면 잘 알것이고, Python만 공부한사람이면 같은거 아닌가? 라고 생각할 것이다.
두개는 명백히 차이가 있다.
Array는 메모리 사이즈가 고정되어있고, List는 메모리 사이즈를 할당할 수 있다.
고정되어있는 Array가 접근 속도가 더 좋다. 정도만 알면 될것이다.
Set과 Map 활용하기
Set은 중복이 없는정해진 순서가 없는 요소들의 집합을 나타내는 컬렉션이다.
Map은 요소가 키와 값이 쌍 형태로 저장되는 컬렉션인데, 키는 중복될 수 없고 값은 중복될 수 있다.
Set 생성하기
불변형 SetOf()함수
package chap09.section3
fun main() {
val mixedTypesSet = setOf("Hello", 5, "world", 3.14, 'c') // 자료형 혼합 초기화
var intSet: Set<Int> = setOf<Int>(1, 5, 5) // 정수형만 초기화
println(mixedTypesSet)
println(intSet)
}
가변형 mutableSetOf() 함수
package chap09.section3
fun main() {
// 불변형 Set 정의하기
val animals = mutableSetOf("Lion", "Dog", "Cat", "Python", "Hippo")
println(animals)
// 요소의 추가
animals.add("Dog") // 요소 중 "Dog"가 이미 존재하므로 변화 없음
println(animals)
// 요소의 삭제
animals.remove("Python")
println(animals)
}
HashSet
해시 테이블이란 내부적으로 키와 인덱스를 이용해 검색과 변경 등을 매우 빠르게 처리할 수 있는 자료구조이다.
hashSetOf()는 HashSet를 반환하는데 HashSet는 불변성 선언이 없기 때문에 추가 및 삭제 등의 기능을 수행할 수 있다.
Treeset
이진 탐색트리, 레드 블랙트리 알고리즘을 사용해 자료구조를 생성
기존의 이진 탐색트리가 한쪽으로 치우친 트리 구조를 가지게 되는 경우 트리 높이만큼 시간이 걸리게 되는 최악의 경우가 생김.
레드 블랙트리는 요소를 빨간색과 검은색으로 구분해 치우친 결과 없이 트리의 요소를 배치한다.
따라서 최악으로 요소 배치가 되어서 검색등의 처리에서 일정한 시간을 보장하는 자료구조이다.
HashSet보다 성능이 떨어져도, 검색과 정렬이 뛰아나다는 장점이 있다.
package chap09.section3
import java.util.*
fun main(){
// 자바의 java.utill.TreeSet 선언
val intsSortedSet: TreeSet<Int> = sortedSetOf(4, 1, 7, 2)
intsSortedSet.add(6)
intsSortedSet.remove(1)
println("intsSortedSet = ${intsSortedSet}")
intsSortedSet.clear() // 모든 요소 삭제
println("intsSortedSet = ${intsSortedSet}")
}
linkedSetOf() 함수
링크드 리스트를 사용해 구현된 해시 테이블에 요소를 저장하는것임.
앞서 나온 HashSet, TreeSet보다 느리지만, 포인터 연결을 통해 메모리 저장 공간을 좀 더 효울적으로 사용할 수 있음.
package chap09.section3
fun main(){
// Linked List를 이용한 HashSet
val intsLinkedHashSet: java.util.LinkedHashSet<Int> = linkedSetOf(35, 21, 76, 26, 75)
intsLinkedHashSet.add(4)
intsLinkedHashSet.remove(21)
println(intsLinkedHashSet)
intsLinkedHashSet.clear()
println(intsLinkedHashSet)
}
Map의 활용
Map에서 사용하는 멤버 프로퍼티와 메서드
| 멤버 | 설명 |
| size | Map 컬렉션의 크기를 반환한다. |
| keys | Set의 모든 키를 반환한다. |
| values | Set의 모든 값을 반환한다. |
| isEmpty() | Map이 비어 있는지 확인하고 비어 있으면 true를, 아니면 false 반환 |
| containsKey(key: K) | 인자에 해당하는 키가 있다면 true를, 없으면 false를 반환 |
| containsValue(value: V) | 인자에 해당하는 값이 있다면 true를, 없으면 false를 반환 |
| get(key: K) | 키에 해당하는 값을 반환하며, 없으면 null을 반환한다. |
불변형 Map 사용하기
package chap09.section3
fun main() {
// 불변형 Map의 선언 및 초기화
val langMap: Map<Int, String> = mapOf(11 to "Java", 22 to "Kotlin", 33 to "C++")
for((key, value) in langMap) { // 키와 값의 쌍을 출력
println("key=$key, value=$value")
}
println("langMap[22] = ${langMap[22]}") // 키 22에 대한 값 출력
println("langMap.get(22) = ${langMap.get(22)}") // 위와 동일한 표현
println("langMap.keys = ${langMap.keys}") // 맵의 모든 키 출력
}
가변형 mutableMapOf() 함수
MutableMap에서 사용하는 멤버 메서드
| 멤버 | 설명 |
| put(key: K, value: V) | 키와 값의 쌍을 Map에 추가한다. |
| remove(key: K) | 키에 해당하는 요소를 Map에서 제거한다. |
| putAll(from: Map<out K, V>) | 인자로 주어진 Map 데이터를 갱신하거나 추가한다. |
| clear() | 모든 요소를 지운다. |
package chap09.section3
fun main() {
// 가변형 Map의 선언 및 초기화
val capitalCityMap: MutableMap<String, String> // 선언할 때 키와 값의 자료형을 명시할 수 있음
= mutableMapOf("Korea" to "Seoul", "China" to "Beijing", "Japan" to "Tokyo")
println(capitalCityMap.values) // 값만 출력
println(capitalCityMap.keys) // 키만 출력
capitalCityMap.put("UK", "London") // 요소의 추가
capitalCityMap.remove("China") // 요소의 삭제
println(capitalCityMap)
}
Map에서 사용할 수 있는 다른 기타 자료구조들이 있다.
package chap09.section3
import java.util.SortedMap
fun main() {
// java.util.HashMap 사용
val hashMap: HashMap<Int, String> = hashMapOf(1 to "Hello", 2 to "World")
println("hashMap = $hashMap")
// java.util.SortedMap 사용
val sortedMap: SortedMap<Int, String> = sortedMapOf(1 to "Apple", 2 to "Banana")
println("sortedMap = $sortedMap")
// java.util.LinkedHashMap 사용
val linkedHash: LinkedHashMap<Int, String> = linkedMapOf(1 to "Computer", 2 to "Mouse")
println("linkedHash = $linkedHash")
}
컬렉션의 확장 함수
코틀린의 함수 종류가 상당히 많은데 기능을 기준으로 하여 아래와 같은 범주로 나눌 수 있다.
- 연산자(Operator) 기능의 메서드 : 더하고 빼는 등의 기능
- 집계(Aggregator) 기능의 메서드 : 최대, 최소, 집합, 총합 등의 계산 기능
- 검사(Check) 기능의 메서드 : 요소를 검사하고 순환하는 기능
- 필터(Filterling) 기능의 메서드 : 원하는 요소를 골라내는 기능
- 변환(Transformer) 기능의 메서드 : 뒤집기, 정렬, 자르기 등의 변환 기능
컬렉션의 연산
package chap09.section4
fun main() {
val list1: List<String> = listOf("one", "two", "three")
val list2: List<Int> = listOf(1, 3, 4)
val map1 = mapOf("hi" to 1, "hello" to 2, "Goodbye" to 3)
println(list1 + "four") // + 연산자를 사용한 문자열 요소 추가
println(list2 + 1) // + 연산자를 사용한 정수ㅇ형 요소 추가
println(list2 + listOf(5, 6, 7)) // 두 List의 병합
println(list2 - 1) // 요소의 제거
println(list2 - listOf(3, 4, 5)) // 일치하는 요소의 제거
println(map1 + Pair("Bye", 4)) // Pair()를 사용한 Map의 요소 추가
println(map1 - "hello") // 일치하는 값의 제거
println(map1 + mapOf("Apple" to 4, "Orange" to 5)) // 두 Map의 병합
println(map1 - listOf("hi", "hello")) // List에 일치하는 값을 Map에서 제거
}
요소의 처리와 집계
요소를 집계하는 확장 함수로는 forEach, forEachIndexed, onEach, count, max, min, maxBy, minBy, fold, reduce, sumBy() 등이 있다.
컬렉션의 요소 집계 확장 함수를 사용해보자.
요소의 순환
forEach, forEachIndexed
package chap09.section4
fun main() {
val list = listOf(1, 2, 3, 4, 5, 6)
val listPair = listOf(Pair("A", 300), Pair("B", 200), Pair("C", 100))
val map = mapOf(11 to "Java", 22 to "Kotlin", 33 to "C++")
// forEach: 각 요소를 람다식으로 처리
list.forEach{print("$it ")}
println()
list.forEachIndexed {index, value -> println("index[$index]: $value")} // 인덱스 포함
}
onEach
package chap09.section4
fun main() {
val list = listOf(1, 2, 3, 4, 5, 6)
val listPair = listOf(Pair("A", 300), Pair("B", 200), Pair("C", 100))
val map = mapOf(11 to "Java", 22 to "Kotlin", 33 to "C++")
// onEach: 각 요소를 람다식으로 처리 후 컬렉션으로 반환
val returnedList = list.onEach{print(it)}
println()
val returnedMap = map.onEach{println("key: ${it.key}, value: ${it.value}")}
println("returnedList = $returnedList")
println("returnedMap = $returnedMap")
}
요소의 개수 반환하기
count
package chap09.section4
fun main() {
val list = listOf(1, 2, 3, 4, 5, 6)
val listPair = listOf(Pair("A", 300), Pair("B", 200), Pair("C", 100))
val map = mapOf(11 to "Java", 22 to "Kotlin", 33 to "C++")
// count: 조건에 맞는 요소 개수 반환
println(list.count{it % 2 == 0})
}
최댓값과 최솟값의 요소 반환하기
package chap09.section4
fun main() {
val list = listOf(1, 2, 3, 4, 5, 6)
val listPair = listOf(Pair("A", 300), Pair("B", 200), Pair("C", 100))
val map = mapOf(11 to "Java", 22 to "Kotlin", 33 to "C++")
println(list.max()) // 6
println(list.min()) // 1
// maxBy/minBy: 최댓값과 최솟값으로 나온 요소 it에 대한 식의 결과
println("maxBy: " + map.maxBy {it.key}) // 키를 기준으로 최댓값
println("minBy: " + map.minBy {it.key}) // 키를 기준으로 최댓값
}
각 요소에 정해진 식 적용하기
package chap09.section4
fun main() {
val list = listOf(1, 2, 3, 4, 5, 6)
val listPair = listOf(Pair("A", 300), Pair("B", 200), Pair("C", 100))
val map = mapOf(11 to "Java", 22 to "Kotlin", 33 to "C++")
// fold: 초깃값과 정해진 식에 따라 처음 요소부터 끝 요소에 적용하여 값을 생성
println(list.fold(4) {total, next -> total + next}) // 4 + 1 + ... + 6 = 25
println(list.fold(1) {total, next -> total + next}) // 1 * 1 * 2 * ... * 6 = 720
// foldRight: fold와 같고 마지막 요소에서 처음 요소로 반대로 적용
println(list.foldRight(4) {total, next -> total + next})
println(list.foldRight(1) {total, next -> total * next})
// reduce: fold와 동일하지만 초깃값을 사용하지 않음
println(list.reduce {total, next -> total + next})
println(list.reduceRight {total, next -> total + next})
}
모든 요소 합산하기
sumBy
package chap09.section4
fun main() {
val list = listOf(1, 2, 3, 4, 5, 6)
val listPair = listOf(Pair("A", 300), Pair("B", 200), Pair("C", 100))
val map = mapOf(11 to "Java", 22 to "Kotlin", 33 to "C++")
// sumBy: 식에 의해 도출된 모든 요소를 합산
println(listPair.sumBy{it.second})
}
요소의 검사
요소의 일치 여부 검사하기
all과 any를 사용한다.
package chap09.section4
fun main() {
val list = listOf(1, 2, 3, 4, 5, 6)
val listPair = listOf(Pair("A", 300), Pair("B", 200), Pair("C", 100))
val map = mapOf(11 to "Java", 22 to "Kotlin", 33 to "C++")
// all: 모든 요소가 일치해야 true를 반환
println(list.all{it<10})
println(list.all{it%2==0})
// any: 최소한 하나 혹은 그 이상의 특정 요소가 일치해야 true를 반환
println(list.any {it % 2 == 0})
println(list.any {it > 10})
}
특정 요소의 포함 및 존재 여부 검사하기
앞에서 배웠듯이 contains()를 사용할 수 있다.
package chap09.section4
fun main() {
val list = listOf(1, 2, 3, 4, 5, 6)
val listPair = listOf(Pair("A", 300), Pair("B", 200), Pair("C", 100))
val map = mapOf(11 to "Java", 22 to "Kotlin", 33 to "C++")
// contains: 요소가 포함되어 있으면 true를 반환
println("contains: " + list.contains(2))
println(2 in list)
println(map.contains(11))
println(11 in map)
// containsAll: 모든 요소가 포함되어 있으면 true를 반환
println("containsAll: " + list.containsAll(listOf(1, 2, 3)))
}
none(), inEmpty(), isNotEmpty()를 사용해서 컬렉션에 요소가 있는지 확인할 수 있다.
package chap09.section4
fun main() {
val list = listOf(1, 2, 3, 4, 5, 6)
val listPair = listOf(Pair("A", 300), Pair("B", 200), Pair("C", 100))
val map = mapOf(11 to "Java", 22 to "Kotlin", 33 to "C++")
// none: 요소가 없으면 true, 있으면 false를 반환
println("none: " + list.none())
println("none: " + list.none{ it > 6}) // 6 이상은 없으므로 true를 반환
// isEmpty/isNotEmpty: 컬렉션이 비어 있는지 아닌지 검사
println(list.isEmpty())
println(list.isNotEmpty())
}
요소의 필터와 추출
특정 요소를 골라내기
package chap09.section4
fun main(){
val list = listOf(1, 2, 3, 4, 5, 6)
val listMixed = listOf(1, "Hello", 3, "World", 5, 'A')
val listWithNull = listOf( 1, null, 3, null, 5, 6)
val listRepeated = listOf(2, 2, 3, 4, 5, 5, 6)
val map = mapOf(11 to "Java", 22 to "Kotlin", 33 to "C++")
// filter: 식에 따라 요소를 골라내기
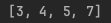
println(list.filter{ it % 2 == 0}) // 짝수만 골라내기
println(list.filterNot {it % 2 == 0}) // 식 이외에 요소 골라내기
println(listWithNull.filterNotNull()) // null을 제외
}
특정 인덱스와 함께 추출하도록 메서드 이름에 Indexed가 붙은 메서드를 사용해보자
package chap09.section4
fun main(){
val list = listOf(1, 2, 3, 4, 5, 6)
val listMixed = listOf(1, "Hello", 3, "World", 5, 'A')
val listWithNull = listOf( 1, null, 3, null, 5, 6)
val listRepeated = listOf(2, 2, 3, 4, 5, 5, 6)
val map = mapOf(11 to "Java", 22 to "Kotlin", 33 to "C++")
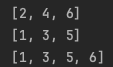
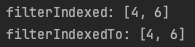
// filterIndexed: 인덱스와 함께 추출
println("filterIndexed: " + list.filterIndexed{idx, value -> idx != 1 && value % 2 == 0})
// filterIndexedTo: 추출 후 가변형 컬렉션으로 변환
val mutList =
list.filterIndexedTo(mutableListOf()) {idx, value -> idx != 1 && value % 2 == 0}
println("filterIndexedTo: $mutList")
}
Map에서 키와 값에 대한 필터도 가능하다.
package chap09.section4
fun main(){
val list = listOf(1, 2, 3, 4, 5, 6)
val listMixed = listOf(1, "Hello", 3, "World", 5, 'A')
val listWithNull = listOf( 1, null, 3, null, 5, 6)
val listRepeated = listOf(2, 2, 3, 4, 5, 5, 6)
val map = mapOf(11 to "Java", 22 to "Kotlin", 33 to "C++")
// filterKeys/filterValues: Map의 키, 값에 따라 추출
println("filterKeys: " + map.filterKeys { it != 11 }) // 키 11을 제외한 요소
println("filterValues: " + map.filterValues { it == "Java" }) // 값이 "Java"인 요소
}
원하는 자료형을 골라낼 수 있는 filterIsInstance<T>()를 사용해서 String형만 골라내보자
package chap09.section4
fun main(){
val list = listOf(1, 2, 3, 4, 5, 6)
val listMixed = listOf(1, "Hello", 3, "World", 5, 'A')
val listWithNull = listOf( 1, null, 3, null, 5, 6)
val listRepeated = listOf(2, 2, 3, 4, 5, 5, 6)
val map = mapOf(11 to "Java", 22 to "Kotlin", 33 to "C++")
// filterIsInstance: 여러 자료형의 요소 중 원하는 자료형을 골라냄
println("filterIsInstance: " + listMixed.filterIsInstance<String>())
}
특정 범위를 잘라내거나 반환할 수도 있다.
slice()
package chap09.section4
fun main(){
val list = listOf(1, 2, 3, 4, 5, 6)
val listMixed = listOf(1, "Hello", 3, "World", 5, 'A')
val listWithNull = listOf( 1, null, 3, null, 5, 6)
val listRepeated = listOf(2, 2, 3, 4, 5, 5, 6)
val map = mapOf(11 to "Java", 22 to "Kotlin", 33 to "C++")
// slice: 특정 인덱스의 요소들을 잘라서 반환하기
println("slice: " + list.slice(listOf(0, 1, 2)))
}
take 관련 연산을 사용하면 n개의 요소를 가진 List를 반환한다.
package chap09.section4
fun main(){
val list = listOf(1, 2, 3, 4, 5, 6)
val listMixed = listOf(1, "Hello", 3, "World", 5, 'A')
val listWithNull = listOf( 1, null, 3, null, 5, 6)
val listRepeated = listOf(2, 2, 3, 4, 5, 5, 6)
val map = mapOf(11 to "Java", 22 to "Kotlin", 33 to "C++")
// take: n개의 요소를 반환
println(list.take(2)) // 앞 두 요소 반환
println(list.takeLast(2)) // 마지막 두 요소 반환
println(list.takeWhile { it < 3 }) // 조건식에 따른 반환
}
take와는 drop을 통해 반대로 특정 요소를 제외할 수 있다.
package chap09.section4
fun main(){
val list = listOf(1, 2, 3, 4, 5, 6)
val listMixed = listOf(1, "Hello", 3, "World", 5, 'A')
val listWithNull = listOf( 1, null, 3, null, 5, 6)
val listRepeated = listOf(2, 2, 3, 4, 5, 5, 6)
val map = mapOf(11 to "Java", 22 to "Kotlin", 33 to "C++")
// drop: 처음부터 n개의 요소를 제외한 List 반환
println(list.drop(3)) // 앞의 요소 3개 제외하고 반환
println(list.dropWhile{it<3}) // 3 미만을 제외하고 반환
println(list.dropLastWhile { it > 3 }) // 3 초과를 제외하고 반환
}
componentN()를 통해 요소를 반환할 수 있다.
package chap09.section4
fun main(){
val list = listOf(1, 2, 3, 4, 5, 6)
val listMixed = listOf(1, "Hello", 3, "World", 5, 'A')
val listWithNull = listOf( 1, null, 3, null, 5, 6)
val listRepeated = listOf(2, 2, 3, 4, 5, 5, 6)
val map = mapOf(11 to "Java", 22 to "Kotlin", 33 to "C++")
println("component1(): " + list.component1()) // 첫 번째 요소인 1 반환
}

합집합과 교집합
distinct()는 중복을 제거해 List로 반환
intersect는 교집합을 List로 반환
package chap09.section4
fun main(){
val list = listOf(1, 2, 3, 4, 5, 6)
val listMixed = listOf(1, "Hello", 3, "World", 5, 'A')
val listWithNull = listOf( 1, null, 3, null, 5, 6)
val listRepeated = listOf(2, 2, 3, 4, 5, 5, 6)
val map = mapOf(11 to "Java", 22 to "Kotlin", 33 to "C++")
// distinct: 중복 요소는 하나로 취급해 List 반환
println("distinct: " + listRepeated.distinct())
// intersect: 교집합 요소만 골라냄
println("intersect: " + list.intersect(listOf(5, 6, 7, 8)))
}
요소의 매핑
.map()은 주어진 컬렉션의 요소에 일괄적으로 .map()에 있는 식을 적용해 새로운 컬렉션을 만들 수 있게 하는 메서드이다.
forEach()와 비슷해보이나 주어진 컬렉션을 전혀 건드리지 않는다는 점에서 좀 더 안전하다.
package chap09.section4
fun main() {
val list = listOf(1, 2, 3, 4, 5, 6)
val listWithNull = listOf( 1, null, 3, null, 5, 6)
// map: 컬렉션에 주어진 식을 적용해 새로운 컬렉션 반환
println(list.map {it * 2})
// mapIndexed: 컬렉션에 인덱스를 포함하고 주어진 식을 적용해 새로운 컬렉션 반환
val mapIndexed = list.mapIndexed {index, it -> index * it}
println(mapIndexed)
// mapNotNull: null을 제외하고 식을 적용해 새로운 컬렉션 반환
println(listWithNull.mapNotNull {it?.times(2)})
}
flatMap은 각 요소에 식을 적용한 후 이것을 다시 하나로 합쳐 새로운 컬렉션을 반환한다.
package chap09.section4
fun main() {
val list = listOf(1, 2, 3, 4, 5, 6)
val listWithNull = listOf( 1, null, 3, null, 5, 6)
// flatMap: 각 요소에 식을 적용한 후 다시 합쳐 새로운 컬렉션을 반환
println(list.flatMap {listOf(it, 'A')})
val result = listOf("abc", "12").flatMap{it.toList()}
println(result)
}
groupBy는 주어진 식에 따라 요소를 그룹화하고 이것을 다시 Map으로 반환한다.
아래 예제에서는 기존 list에서 홀수와 짝수를 구분해 그룹화 하고 Map으로 반환한다.
package chap09.section4
fun main() {
val list = listOf(1, 2, 3, 4, 5, 6)
val listWithNull = listOf( 1, null, 3, null, 5, 6)
// groupBy: 주어진 함수의 결과에 따라 그룹화하여 map으로 반환
val grpMap = list.groupBy { if (it%2 == 0) "even" else "odd"}
print(grpMap)
}
요소 처리와 검색
요소 처리와 검색 사용하기
주어진 인덱스에 해당하는 요소를 반환하는 elementAt()을 사용할 때 인덱스 범위를 벗어나면 IndexOutOfBoundsException 오류
elementAtOrElse()는 인덱스 범위를 벗어나도 식에 따라 결과를 반환하며,
elementAtOrNull()은 인덱스 범위를 벗어나는 경우 null을 반환.
package chap09.section4
fun main() {
val list = listOf(1, 2, 3, 4, 5, 6)
val listPair = listOf(Pair("A", 300), Pair("B", 200), Pair("C", 100))
val listRepeated = listOf(2, 2, 3, 4, 5, 5, 6)
// elementAt: 인덱스에 해당하는 요소 반환
println("elementAt: " + list.elementAt(1))
// elementAtOrElse: 인덱스를 벗어나는 경우 식에 따라 결과 반환
println("elementAtOrElse: " + list.elementAtOrElse(10, { 2 * it }))
// elementAtOrElse(10) {2 * it} 표현식과 동일
// elementAtOrNull: 인덱스를 벗어나는 경우 null 반환
println("elementAtOrNull: " + list.elementAtOrNull(10))
}
first, last, firstOrNull, lastOrNull을 이용에서 요소 값을 반환할 수 있다.
package chap09.section4
fun main() {
val list = listOf(1, 2, 3, 4, 5, 6)
val listPair = listOf(Pair("A", 300), Pair("B", 200), Pair("C", 100))
val listRepeated = listOf(2, 2, 3, 4, 5, 5, 6)
// first: 식에 일치하는 첫 요소 반환
println("first: " + listPair.first{it.second == 200})
// last: 식에 일치하는 마지막 요소 반환
println("last: " + listPair.last{it.second == 200})
// firstOrNull: 식에 일치하지 않는 경우 null 반환
println("firstOrNull: " + listPair.firstOrNull{it.first == "E"})
// lastOrNull : 식에 일치하지 않는 경우 Null 반환
println("lastOrNull: " + listPair.lastOrNull{it.first == "E"})
}
인덱스도 반환할 수 있다.
앞에서 배운 indexOf(), indexOfFirst{}, lastIndexOf(), indexOfLast{}와 같아 예제를 스킵한다.
single
해당 조건식에 일치하는 요소를 하나 반환한다.
package chap09.section4
fun main() {
val list = listOf(1, 2, 3, 4, 5, 6)
val listPair = listOf(Pair("A", 300), Pair("B", 200), Pair("C", 100))
val listRepeated = listOf(2, 2, 3, 4, 5, 5, 6)
// single: 람다식에 일치하는 요소 하나 반환
println("single: " + listPair.single{it.second == 100})
println("singleOrNull: " + listPair.singleOrNull{it.second == 500})
}
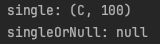
single은 일치하는 요소가 하나 이상인 경우 예외를 발생하는데,
singleOrNull은 조건식에 일치하는 요소가 없거나 일치하는 요소가 하나 이상이면 null을 반환한다.
검색을 위한 메서드가 2개가 더 있다.
우리가 이진탐색이라고 알고 있는 binarySearch와 find가 있다.
package chap09.section4
fun main() {
val list = listOf(1, 2, 3, 4, 5, 6)
val listPair = listOf(Pair("A", 300), Pair("B", 200), Pair("C", 100))
val listRepeated = listOf(2, 2, 3, 4, 5, 5, 6)
// binarySearch: 요소에 대해 이진 탐색 후 인덱스 반환
println("binarySearch: " + list.binarySearch(3))
// find: 조건식을 만족하는 첫 번째 검색된 요소 반환, 없으면 null
println("find: " + list.find{it > 3})
}
컬렉션의 분리와 병합
union()을 통해 합집합을 나타낼 수 있고,
plus()나 +연산자를 사용하면 중복을 허용하는 합집합을 나타낼 수 있다.
package chap09.section4
fun main() {
val list1 = listOf(1,2,3,4,5,6)
val list2 = listOf(2,2,3,4,5,5,6,7)
// union: 두 List를 합침(중복 요소 하나만)
println(list1.union(list2))
// plus: 두 List를 합침(중복 요소 포함)
println(list1.plus(list2))
}
partition을 통해 주어진식에 따라 2개의 컬렉션으로 분리할 수 있다.
package chap09.section4
fun main() {
val list1 = listOf(1,2,3,4,5,6)
val part = list1.partition { it % 2 == 0 }
println(part)
}
zip()은 2개의 컬렉션에서 동일한 인덱스끼리 Pair를 만들 수 있다.
package chap09.section4
fun main() {
val list1 = listOf(1,2,3,4,5,6)
val list2 = listOf(2,2,3,4,5,5,6,7)
// partition: 동일 인덱스끼리 Pair를 만들어 반환
val zip = list1.zip(listOf(7, 8))
println(zip)
}
순서와 정렬
파이썬의 정렬과 비슷하다.
package chap09.section4
fun main() {
// reversed: 뒤집힌 순서로 컬렉션 반환
val unsortedList = listOf(3, 2, 7, 5)
println(unsortedList.reversed())
// sorted: 요소를 정렬한 후 정렬된 컬렉션 반환
println(unsortedList.sorted())
// sortedDescneding: 내림차순 정렬
println(unsortedList.sortedDescending())
// sortedBy: 특정 비교식에 의해 정렬된 컬렉션 반환
println(unsortedList.sortedBy {it % 3})
println(unsortedList.sortedByDescending { it % 3 })
}
시퀀스 활용하기
요소 값 생성하기
generateSequence()로 성생하기
package chap09.section5
fun main() {
// 시드 값 1을 시작으로 1씩 증가하는 시퀀스 정의
val nums: Sequence<Int> = generateSequence (1){ it + 1 }
// take()를 사용해 원하는 요소 개수만큼 획득하고 toList()를 사용해 List 컬렉션으로 반환
println(nums.take(10).toList())
}
generateSequence를 사용해 시드 인수에 1을 주고 1씩 증가하도록 시퀀스를 정의했습니다.
take(10)을 통해 원하는 갯수만큼 요소가 저장되고 List로 반환한다.
package chap09.section5
fun main() {
// 시드 값 1을 시작으로 1씩 증가하는 시퀀스 정의
val nums: Sequence<Int> = generateSequence (1){ it + 1 }
val squares = generateSequence(1) { it + 1 }.map {it * it}
println(squares.take(10).toList())
val oddSquares = squares.filter {it % 2 != 0}
println(oddSquares.take(5).toList())
}
요소 값 가져오기
메서드 체이닝의 중간 결과 생성하기
아래 코드는 순차적 연산이기 때문에 시간이 많이 걸릴 수 있다.
package chap09.section5
fun main() {
val list1 = listOf(1, 2, 3, 4, 5)
val listDefault = list1
.map{println("map($it)"); it * it}
.filter{println("filter($it) "); it % 2 == 0}
println(listDefault)
}
하지만 asSequence()를 사용하면 병렬처리되기 때문에 처리 성능이 좋아진다.
package chap09.section5
fun main() {
val list1 = listOf(1, 2, 3, 4, 5)
val listSeq = list1.asSequence()
.map {print("map($it) "); it * it}
.filter {println("filter($it)"); it % 2 == 0}
.toList()
println(listSeq)
}
코틀린에서 asSequence()를 통해 시간 성능을 알 수 있다.
package chap09.section5
fun main(){
val listBench = (1..1_000_000).toList()
timeElapsed{
listBench
.map{it+1}
.first{it % 100 == 0}
}
timeElapsed{
listBench
.asSequence()
.map{it % 100 == 0}
}
}
fun timeElapsed(task:() -> Unit){
val before = System.nanoTime()
task()
val after = System.nanoTime()
val speed = (after - before) / 1_000
println("$speed ns")
}
시퀀스를 이용해서 피보나치 수열도 출력할 수 있다.
package chap09.section5
fun main() {
val fibonacci = generateSequence(1 to 1){ it.second to it.first + it.second }
.map {it.first}
println(fibonacci.take(10).toList())
}
(47번째 부터 overflow가 발생한다.)

시퀀스를 이용한 소수를 출력할 수 있다.
package chap09.section5
fun main() {
val primes = generateSequence (2 to generateSequence (3){ it + 2 }) {
val currSeq = it.second.iterator()
val nextPrime = currSeq.next()
nextPrime to currSeq.asSequence().filter {it % nextPrime != 0}
}.map {it.first}
println(primes.take(10).toList())
}
'책 리뷰 > Do it! 코틀린 프로그래밍' 카테고리의 다른 글
| 11주차 - 코루틴과 동시성 프로그래밍 (0) | 2024.01.15 |
|---|---|
| 10주차 - 표준 함수와 파일 입출력 (0) | 2024.01.12 |
| 8주차 - 제네릭과 배열 (1) | 2024.01.11 |
| 7주차 - 다양한 클래스와 인터페이스 (0) | 2024.01.09 |
| 6주차 - 프로퍼티와 초기화 (3) | 2024.01.09 |





댓글 영역