고정 헤더 영역
상세 컨텐츠
본문
이번년도에 스마트해상물류 공모전을 참가하면서 스파르타코딩클럽 수강권 1장을 받게되어, 평소에 궁금하던 머신러닝을 수강하게 되었습니다.
대학생분들은 한이음 혹은 스마트해상물류 프로젝트를 진행하는거 추천드려요
(수많은 기프티콘, 프로젝트기회, 멘토들의 조언, 수강권 등 많은 혜택이 있습니다.)
머신러닝 1주차 과제를 위해서 티스토리에 글을 쓰게 되었습니다 !
1주차 과제는 혼자서 Linear Regression을 구현하는 문제입니다.
- 연차-연봉 데이터셋 살펴보기 https://www.kaggle.com/rsadiq/salary
- Learning rate(lr)를 바꾸면서 실험하기
- Optimizer를 바꾸면서 실험하기
- 손실함수(loss)를 mean_absolute_error 로 바꿔서 실험하기
먼저 과제를 하기전에 저 처럼 머신러닝에 처음 접하신 분들도 있으실텐데요
TensorFlow라는 것은 들어봤어도 Colab은 이번에 처음 들어봤는데요
구글에서 Colab을 통해 python을 작성할 수 있습니다.
기존 데스크탑이나 노트북을 사용하면서 python을 이용하는데에 라이브러리파일하고 깔기 정말 귀찮았는데,
그 단점을 완벽하게 보완해준 tool입니다 !
1. 연차-연봉 데이터셋 살펴보기
kaggle 에서 salary데이터셋을 받아와야해서
import os
os.environ['KAGGLE_USERNAME'] = 'junhyeongrhee' # username
os.environ['KAGGLE_KEY'] = '29623a538283c318c691934b784d79c0' # key
!kaggle datasets download -d rsadiq/salary #데이터셋 다운로드
!unzip salary.zip #데이터셋 알집 해제kaggle에 아직 익숙하지 않으신분들을 위해서 내일 kaggle에 관한글을 올리겠습니다 !
해제가 끝났으면 colab은 동기화 하는 속도가 느려 파란원이 쳐진 버튼을 클릭합니다.
그렇게 하면 Salary.csv파일이 나오는데 csv파일은 콤마로 구별되는 파일이라고 하네요
저렇게 csv파일이 나올경우, csv파일을 더블클릭하면
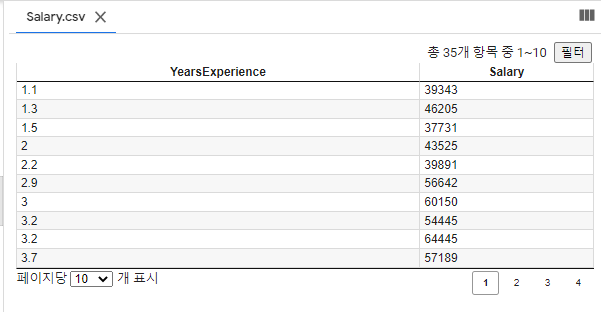
이러한 데이터셋을 볼 수 있습니다.
더블클릭 외에 보는 방법은
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam, SGD
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
df = pd.read_csv('Salary.csv')
df.head(5)이런식으로 코드를 입력하면
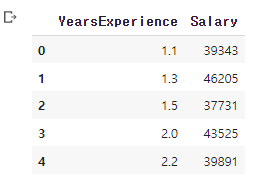
이렇게 출력이 됩니다.
1. 연차-연봉 데이터셋 살펴보기 CLEAR !
2. Learning Rate(lr) 바꾸면서 실험하기
그리고 아래와 같은 소스를 입력합니다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam, SGD #optimizer 2개
import numpy as np #여기까지는 머신러닝공통 import
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
df = pd.read_csv('Salary.csv')
x_data = np.array(df[['YearsExperience']], dtype=np.float32)
y_data = np.array(df['Salary'], dtype=np.float32)
x_data = x_data.reshape((-1, 1))
y_data = y_data.reshape((-1, 1))
print(x_data.shape)
print(y_data.shape)
x_train, x_val, y_train, y_val = train_test_split(x_data, y_data, test_size=0.2, random_state=2021)
print(x_train.shape, x_val.shape)
print(y_train.shape, y_val.shape)
model = Sequential([
Dense(1)
])
model.compile(loss='mean_squared_error', optimizer=Adam(lr=0.1))
model.fit(
x_train,
y_train,
validation_data=(x_val, y_val), # 검증 데이터를 넣어주면 한 epoch이 끝날때마다 자동으로 검증
epochs=100 # epochs 복수형으로 쓰기!
)여기서는 lr(learning rate)가 0.1이 나옵니다.
lr을 더 높여주면 높여줄수록 loss가 줄어드는거를 볼 수 있습니다.




loss뿐만아니라 val_loss도 줄어드는것을 확인할 수 있습니다.
2. Learning Rate(lr) 바꾸면서 실험하기 CLEAR !
3. optimizer 바꾸면서 실험하기
그리고 이제 바로 위에 올린코드에서 import과정중에 셋째줄을 보면
from tensorflow.keras.optimizers import Adam, SGD가 있는데 optimizer를 Adam과 SGD를 사용할 수 있는데 앞선 실험에서는 Adam을 사용했으므로 이번에는 SGD를 사용하겠습니다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam, SGD
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
df = pd.read_csv('Salary.csv')
x_data = np.array(df[['YearsExperience']], dtype=np.float32)
y_data = np.array(df['Salary'], dtype=np.float32)
x_data = x_data.reshape((-1, 1))
y_data = y_data.reshape((-1, 1))
print(x_data.shape)
print(y_data.shape)
x_train, x_val, y_train, y_val = train_test_split(x_data, y_data, test_size=0.2, random_state=2021)
print(x_train.shape, x_val.shape)
print(y_train.shape, y_val.shape)
model = Sequential([
Dense(1)
])
model.compile(loss='mean_squared_error', optimizer=SGD(lr=0.1))#Adam에서 SGD로 교체
model.fit(
x_train,
y_train,
validation_data=(x_val, y_val), # 검증 데이터를 넣어주면 한 epoch이 끝날때마다 자동으로 검증
epochs=100 # epochs 복수형으로 쓰기!
)30번째 줄에 optimizer변수에서 Adam에서 SGD로 교체된걸 확인할 수 있고, 이 코드를 돌리면?
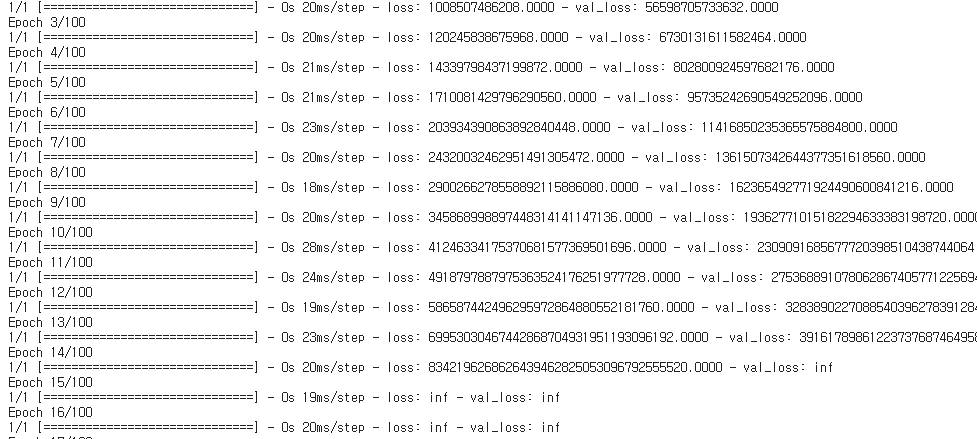
loss가 엄청 커진거를 확인할 수 있습니다.
만족하지는 않지만
3. optimizer 바꾸면서 실험하기 CLEAR !
4. 손실함수 바꾸면서 실험하기
마지막으로 손실함수를 바꾸겠습니다.
기존에 손실함수는
model.compile(loss='mean_squared_error', optimizer=Adam(lr=0.1))mean_squared_error'을 사용했는데요, 이번에는 mean_absolute_error'를 사용해보겠습니다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam, SGD
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
df = pd.read_csv('Salary.csv')
x_data = np.array(df[['YearsExperience']], dtype=np.float32)
y_data = np.array(df['Salary'], dtype=np.float32)
x_data = x_data.reshape((-1, 1))
y_data = y_data.reshape((-1, 1))
print(x_data.shape)
print(y_data.shape)
x_train, x_val, y_train, y_val = train_test_split(x_data, y_data, test_size=0.2, random_state=2021)
print(x_train.shape, x_val.shape)
print(y_train.shape, y_val.shape)
model = Sequential([
Dense(1)
])
model.compile(loss='mean_absolute_error', optimizer=Adam(lr=0.1))
model.fit(
x_train,
y_train,
validation_data=(x_val, y_val), # 검증 데이터를 넣어주면 한 epoch이 끝날때마다 자동으로 검증
epochs=100 # epochs 복수형으로 쓰기!
)
loss가 확 줄어든것을 확인할 수 있습니다.
4. 손실함수 바꾸면서 실험하기 CLEAR !
추가적으로
optimizer=SGD, loss='mean_absolute_error'면 어떨까 라는 생각을 가졌습니다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam, SGD
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
df = pd.read_csv('Salary.csv')
x_data = np.array(df[['YearsExperience']], dtype=np.float32)
y_data = np.array(df['Salary'], dtype=np.float32)
x_data = x_data.reshape((-1, 1))
y_data = y_data.reshape((-1, 1))
print(x_data.shape)
print(y_data.shape)
x_train, x_val, y_train, y_val = train_test_split(x_data, y_data, test_size=0.2, random_state=2021)
print(x_train.shape, x_val.shape)
print(y_train.shape, y_val.shape)
model = Sequential([
Dense(1)
])
model.compile(loss='mean_absolute_error', optimizer=SGD(lr=0.1))
model.fit(
x_train,
y_train,
validation_data=(x_val, y_val), # 검증 데이터를 넣어주면 한 epoch이 끝날때마다 자동으로 검증
epochs=100 # epochs 복수형으로 쓰기!
)
optimizer을 SGD로 썼는데도 불구하고, loss가 더 줄어든것을 확인할 수 있습니다.
이번 1주차 강의를 통해 몰랐던 tool과 머신러닝에 대한 흥미가 생겨서 정말 좋았습니다.
기존에 접했던 코딩과 개념이 달라서 헷갈리긴했으나 관심이 더 생기게 된 계기가 된것 같습니다.
본 코드의 출처는 스파르타코딩클럽 이태희튜터님의 코드를 첨가했습니다.
'공부 > AI' 카테고리의 다른 글
| CUDA가 아닌 MPS로 MNIST학습 (0) | 2022.06.23 |
|---|---|
| CNN으로 풍경 사진을 분류 (0) | 2021.08.05 |
| 딥러닝으로 손글씨 실습 (0) | 2021.07.20 |
| Binary Logical Regression 구현 (0) | 2021.07.20 |





댓글 영역